Estrategia de Acceso a Datos en Quarkus
Estrategias de Acceso de Datos en Quarkus
Contexto
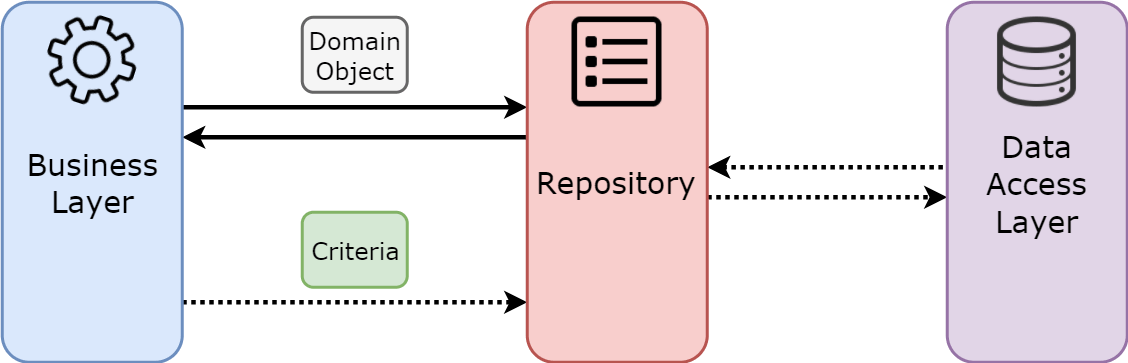
Si venimos desarrollando en un framework como puede ser el caso de uno de los líderes indiscutibles, Spring Boot, podemos darnos cuenta que este usa el patrón repositorio para el acceso a datos, donde abstrae la capa de datos como podemos ver en la imagen.
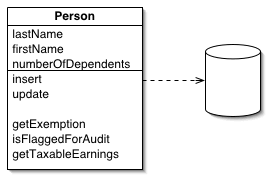
Otra estrategia, si vienes de desarrollar aplicaciones servidor en Ruby on Rails o en Django, es conocida como el patrón Active Record, que es un patrón que facilita el acceso a datos desde el mismo modelo de datos. Es como si tuviera el repositorio de datos en la misma entidad, dándole la posibilidad a esta entidad o modelo de poder traer datos, guardar datos, actualizar los datos y eliminar datos como si fuera un repositorio.
En Quarkus podemos aplicar los dos patrones y aquí te explicaré cómo.
Panache
Antes de eso, déjame explicarte qué es Panache. La función de Panache es poder simplificar y reducir la complejidad del acceso a datos al ser más intuitivo y facilitando las consultas que comúnmente se realizan en la base de datos.
Una vez aclarado esto, crearemos nuestro proyecto de Quarkus.
En este caso, crearemos una pequeña entidad, usando como gestor de base PostgreSQL, pero si tienes MySQL no hay ningún problema.
Aquí puedes generar tu proyecto: https://code.quarkus.io/.
Usaré Java 17 y Maven con las siguientes extensiones:
- REST: Permite crear API RESTful.
- REST Jackson: Compatibilidad con Jackson.
- Hibernate ORM with Panache: Simplifica el código de persistencia para Hibernate ORM. Se pueden usar los patrones mencionados anteriormente.
- JDBC Driver - PostgreSQL: Conectar la aplicación con una base de datos PostgreSQL.
Una vez generado el proyecto, lo abrimos en nuestro IDE de preferencia, en mi caso IntelliJ IDEA.
Modelo de Datos
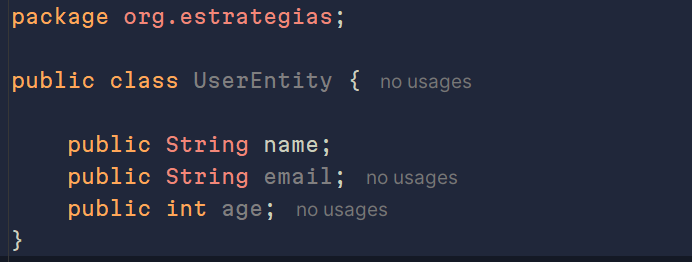
Nuestro modelo de datos será el siguiente, uno bastante simple para el ejemplo.
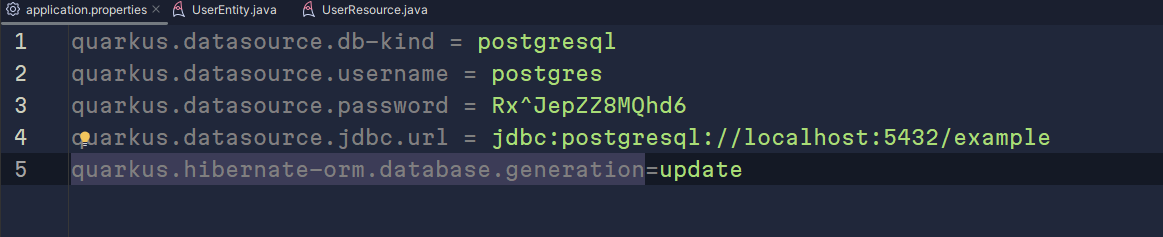
Además, configuramos nuestro acceso a la base de datos desde nuestro application.properties.
Estrategia Active Record
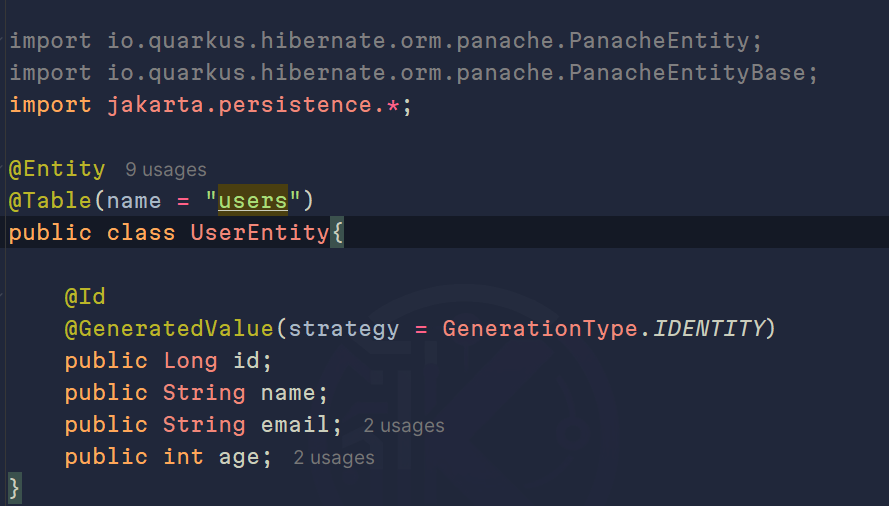
Ahora comenzaremos a definirlo como una entidad y, a la vez, usando el acceso a datos Active Record. Cuando usamos esta estrategia, sus columnas o atributos son públicos y extendemos de PanacheEnity, se vería algo así:
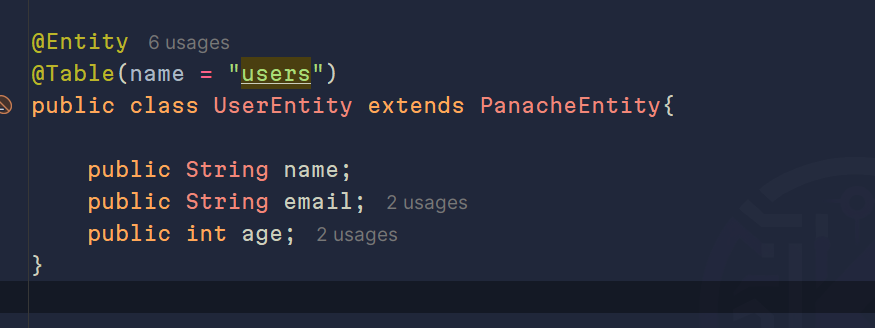
Si te percatas, no definimos el atributo que será nuestro id, y es porque PanacheEntity:
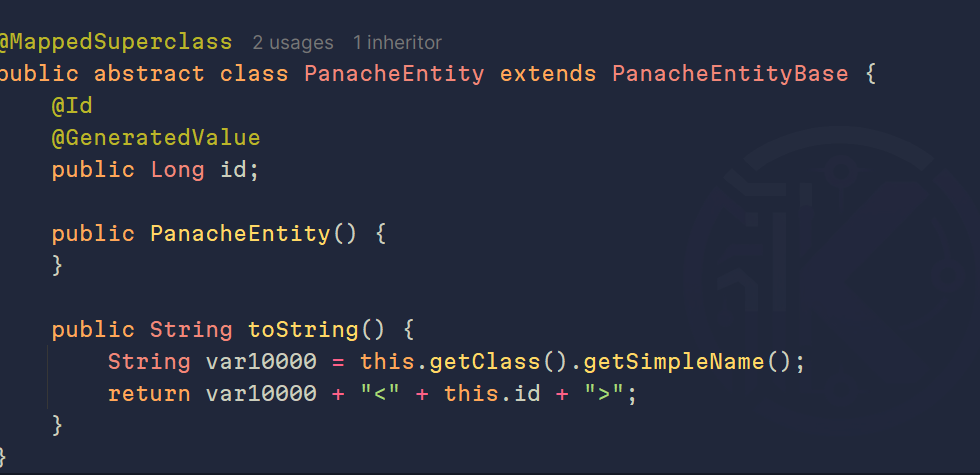
Por defecto, maneja el id como un Long, pero en tal caso quieras manejar otro identificador, podrás extender de PanacheEntityBase, que es lo que normalmente me gusta usar.
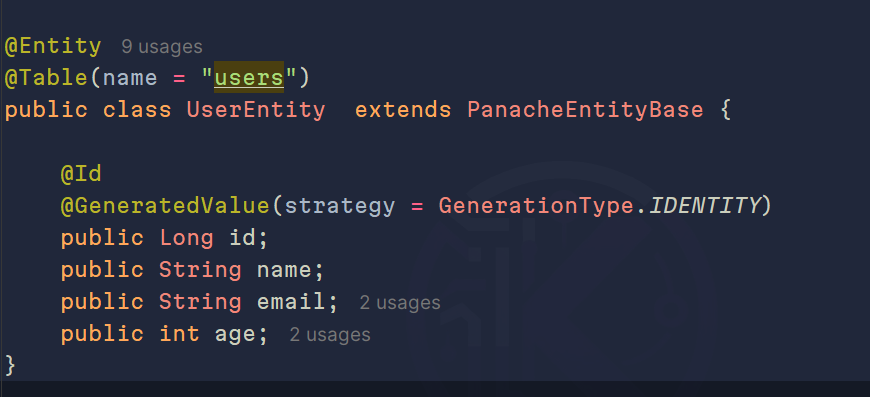
De esta manera, la entidad UserEntity podrá persistirse y traer datos de manera rápida. Aquí te muestro cómo se vería nuestro controlador:
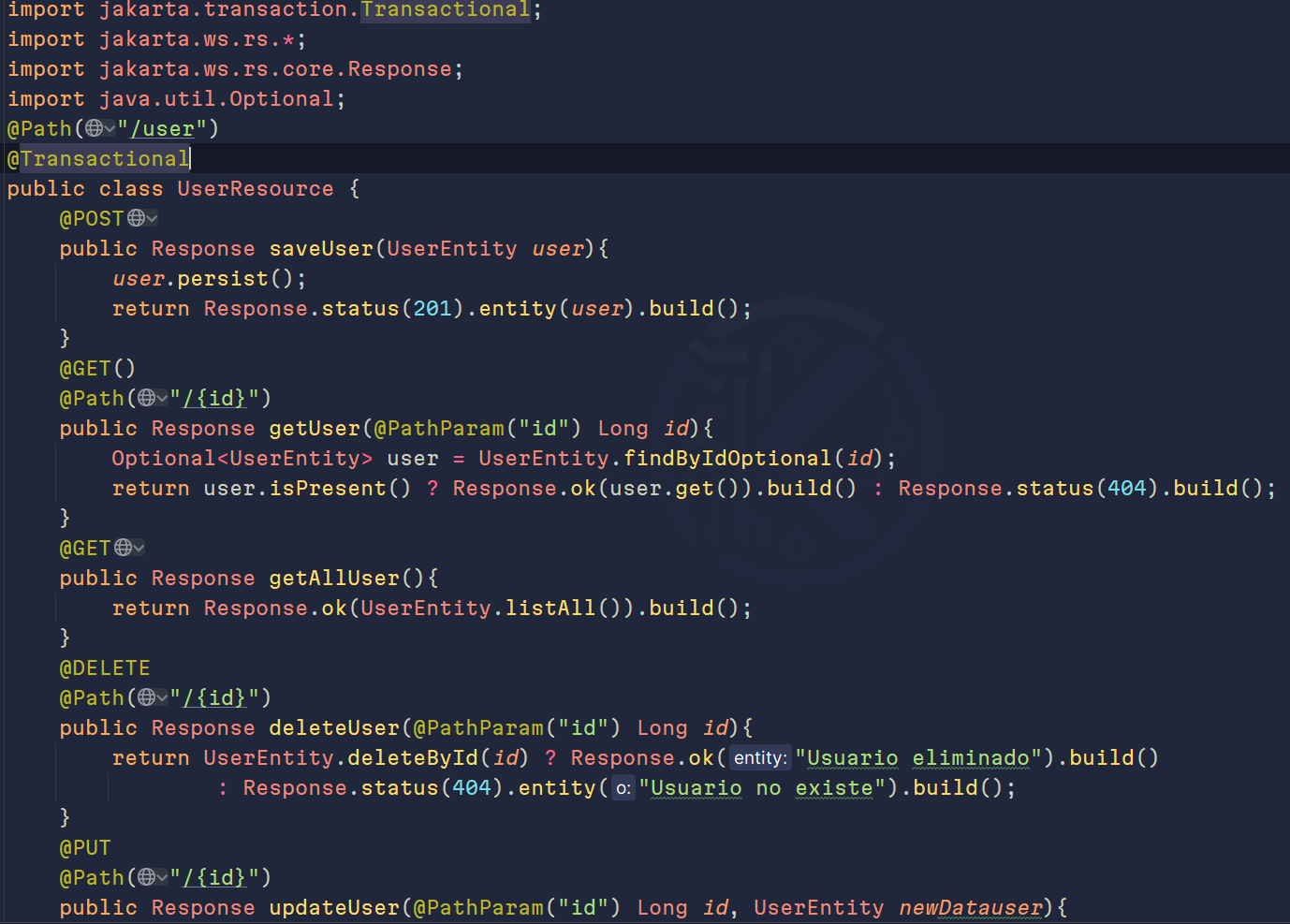
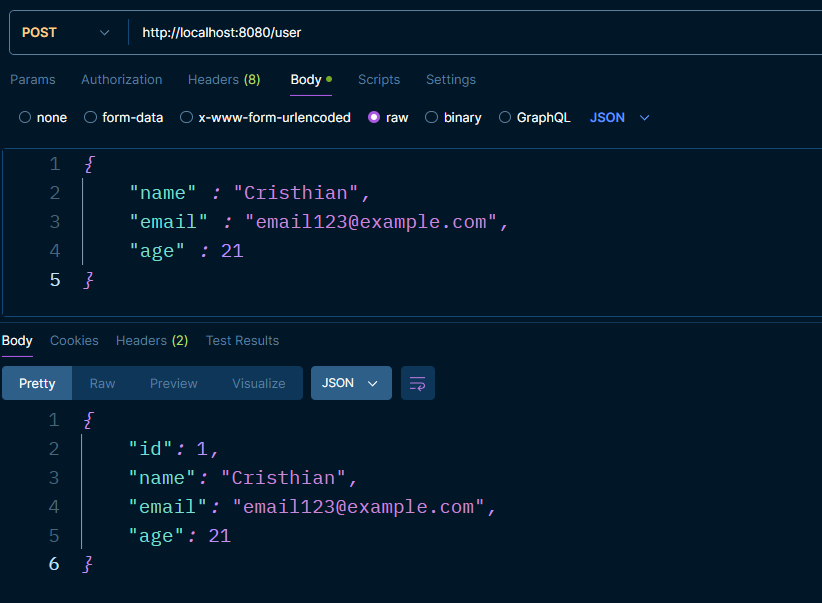
Como podemos ver en la línea 9, nuestro propio usuario se guarda en la base de datos. De la misma manera, desde la clase UserEntity podemos buscar nuestros usuarios, eliminarlos y actualizarlos, agilizando la calidad del código y reduciendo el número de clases. Algo a aclarar es que debemos anotar los endpoints con @Transactional si van a alterar algo en la tabla, ya sea guardar, eliminar, etc. Por eso es mejor ponerla a nivel de clase.
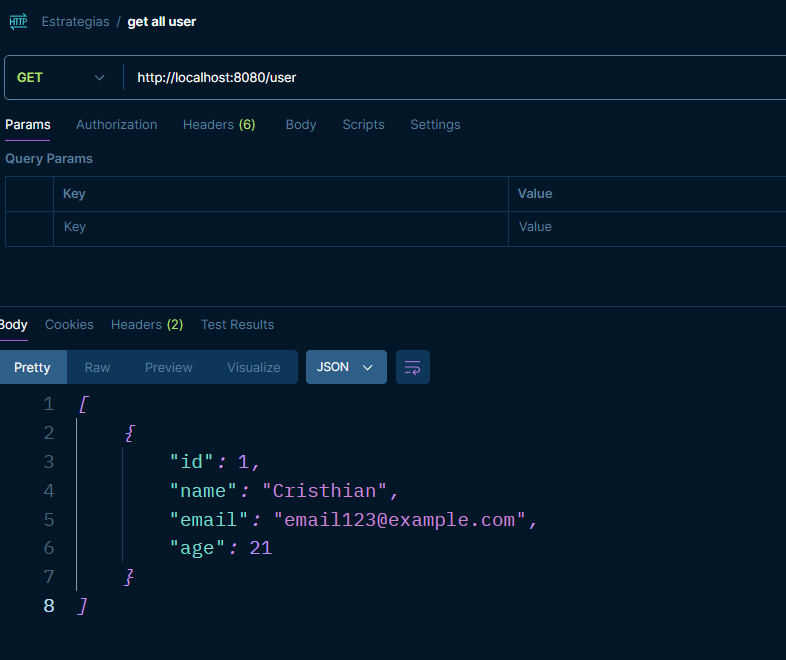
Probemos nuestros endpoints
Recordatorio: el puerto por defecto es el :8080.
POST
GET
Estrategia Patrón Repository
Para este patrón, separamos la capa de datos del modelo de datos, creando una nueva clase repository que será inyectada para su uso.
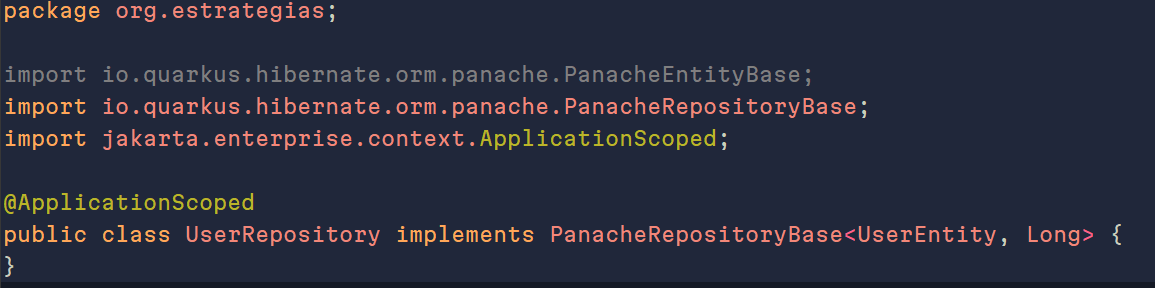
Modelo de Datos
Vemos que ya no extendemos de PanacheEntity, sino que ahora vamos a crear un nuevo archivo/clase donde usaremos PanacheRepository. Si usamos este, solo ponemos nuestra entidad. Pero si usamos PanacheRepositoryBase<NuestraEntidad, NuestroId>:
Y ahora nuestro controlador se ve de la siguiente manera:
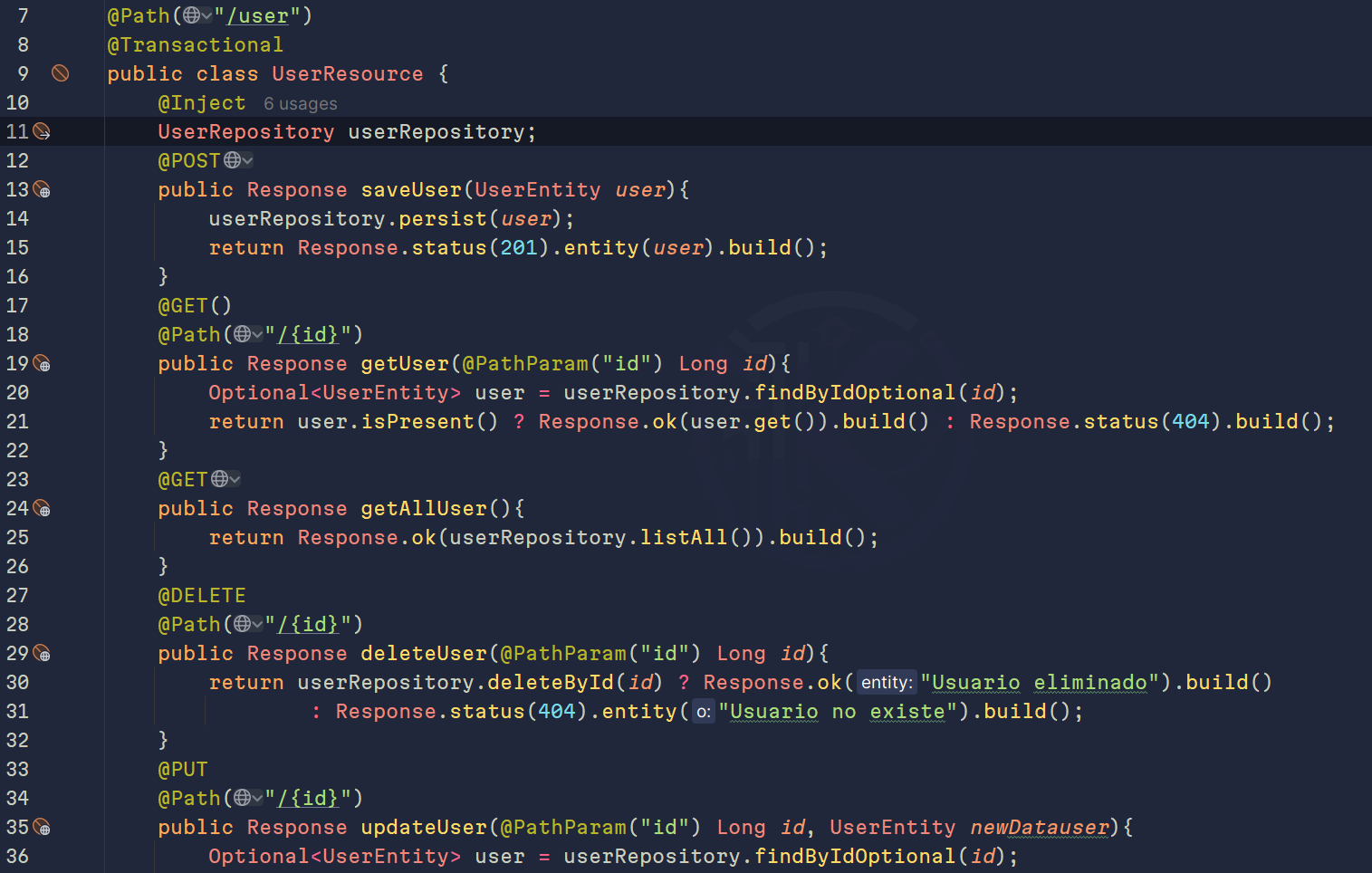
Si nos percatamos, nos damos cuenta que en la línea 11 inyectamos nuestro repository para acceder y manipular nuestros datos.
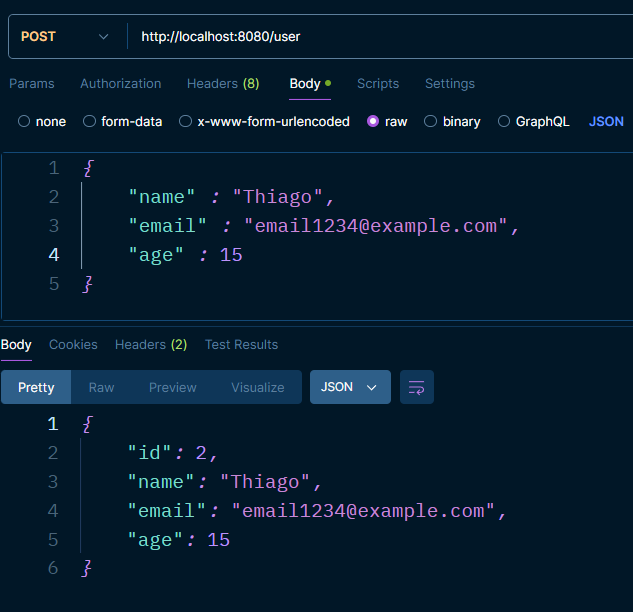
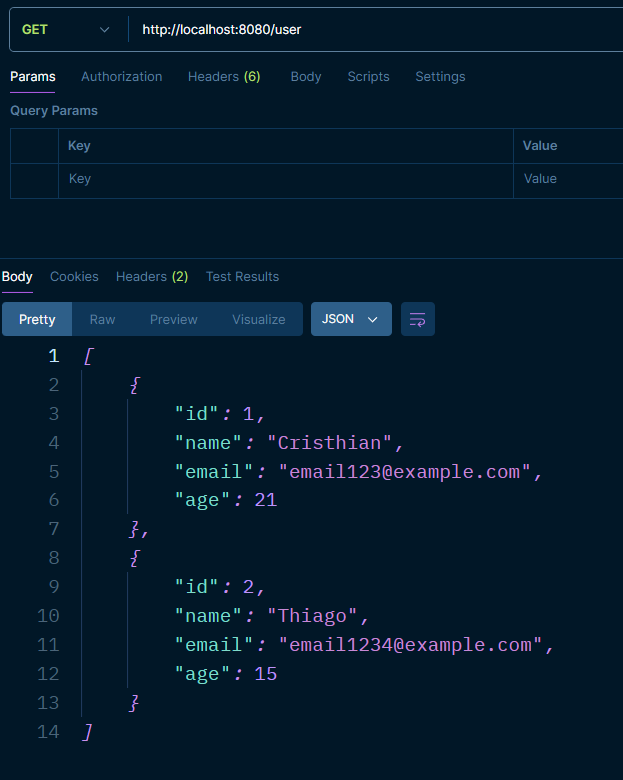
Probemos nuestros endpoints
Recordatorio: el puerto por defecto es el :8080.
POST
GET
Gracias por leer esto.